DeepVA Web Application
How to start a job
DeepVA is based on a simple idea: You choose a mining module (for example Face Recognition) and apply this functionality on any image or video file. The module will automatically generate meta data depending on the module you have chosen.
Start by clicking on “Start Visual Mining”.
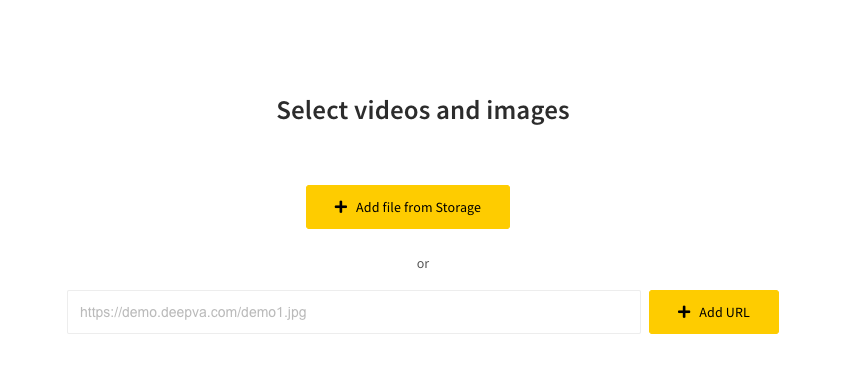
Next, it’s time to select an image or video you want to analyze. There a several different supported media types. You can use a publicly available URL or data you have already uploaded to your storage.
After having selected an image or video you choose a so-called visual mining module which you want to apply. The type of recognition function you choose, will determine what kind of meta data is extracted from your input source.
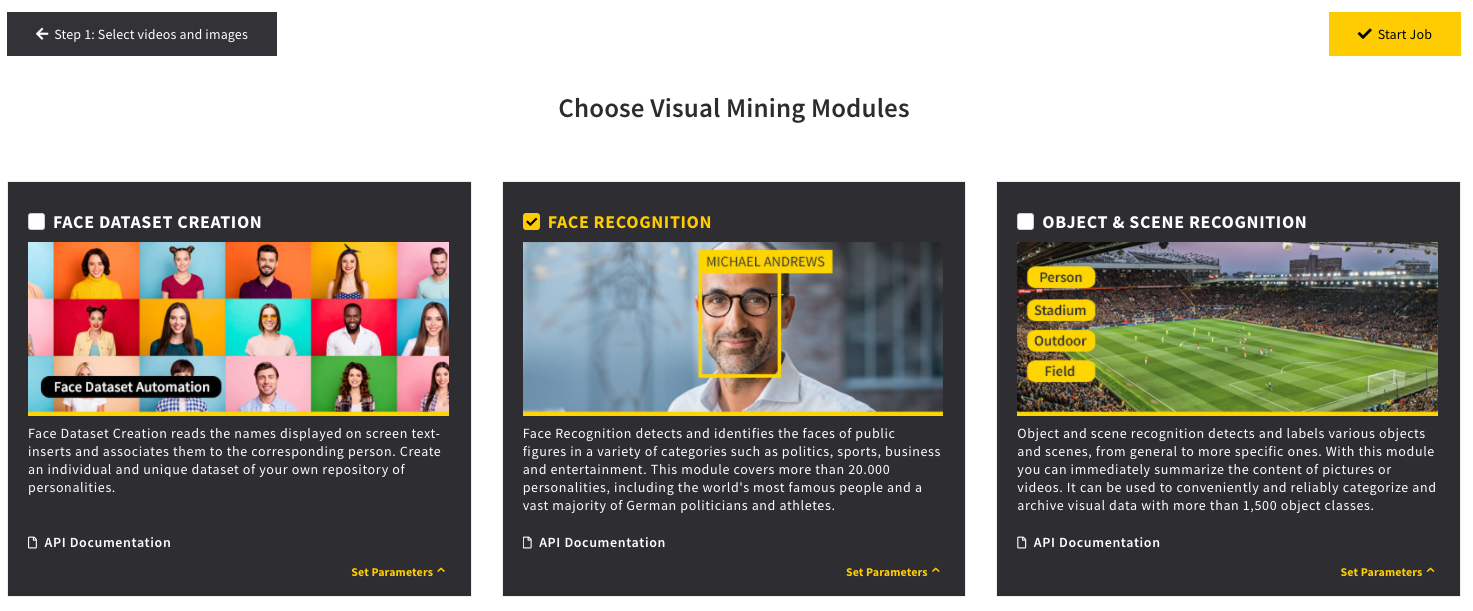
Click on „Start Job“ in the top tight corner and DeepVA will start your analysis.

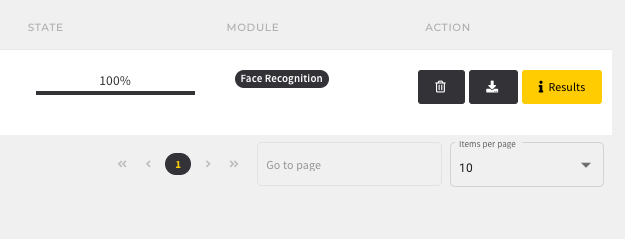
After starting the job, you will be automatically directed to the job overview page.
Now you can review the status of your initiated job(s). Once a job is finished, you can retrieve details of your analysis under “Results”. For more information on jobs, click here.
How to use the storage
Additional to providing an URL of images and videos you want to analyze, you can also start jobs with data you have uploaded to the storage. You can find the storage in the menu on the left.
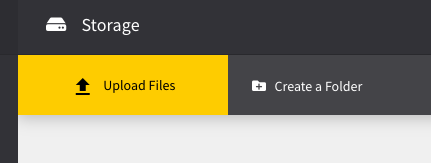
You can either simply upload images or video to your storage by clicking on “Upload Files” or you can create different folders to further structure your data.
For more information on the storage click here.
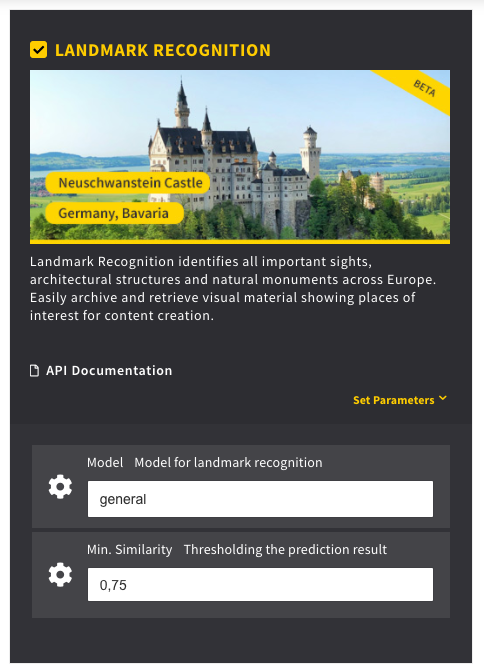
AI models explained
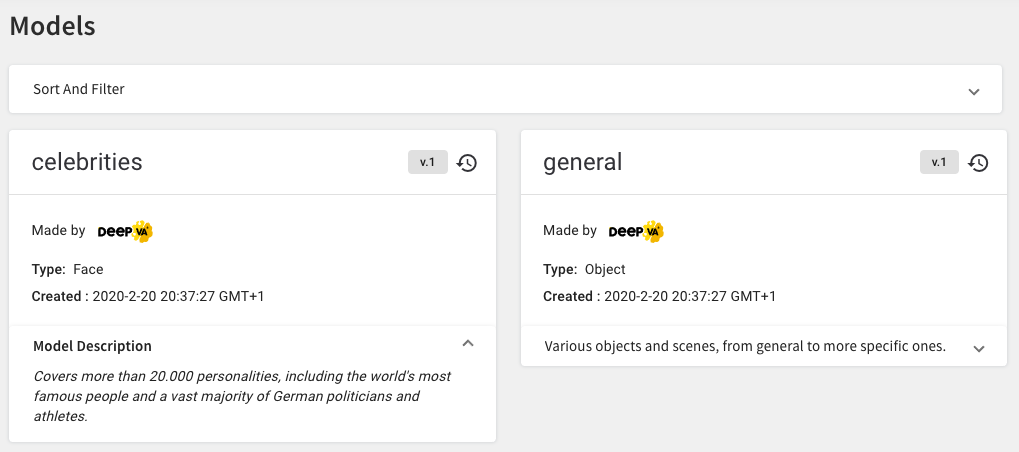
If you click on „AI Models” in the menu on the left, you will find four pre-trained AI models which were created by DeepVA.

AI models form the computer vision basis for extracting meta data from images and videos. Our pre-trained models are used for Face Recognition, Object & Scene Recognition and Landmark Recognition. They include over 20.000 personalities, various objects and scenes and landmarks in Europe and all across the world.
For more information on AI models, click here.
How to create your own AI model
In some cases, DeepVA’s pre-trained models might not recognize certain people or landmarks because they are very specific and maybe not too well known. However, if you want to integrate people or landmarks in your analysis because they are relevant to your requirements, you can create a dataset and train your own AI model.
How to create a dataset
In order to create your own AI model, you have to create a dataset first. A dataset consists of classes (for example “Angela Merkel”) and classes consist of images of that person. Landmarks work in a similar fashion. For more information on datasets, click here.
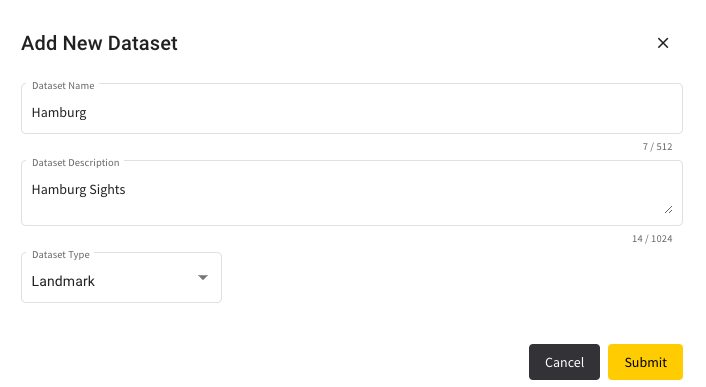
To create a new dataset, go to “Datasets” in the menu on the left and click on “Add New Dataset”.

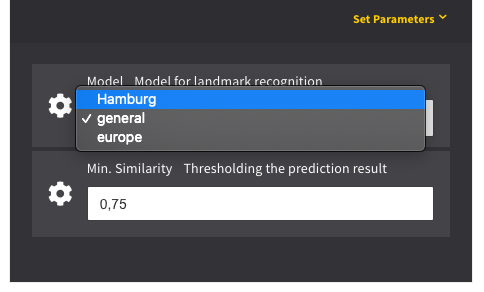
You can now enter the name, a description and the type of dataset. For Face Recognition, choose “Face” and for Landmark Recognition choose “Landmark”. In this case, the dataset name Is “Hamburg”. Click on submit and you will create a new dataset.
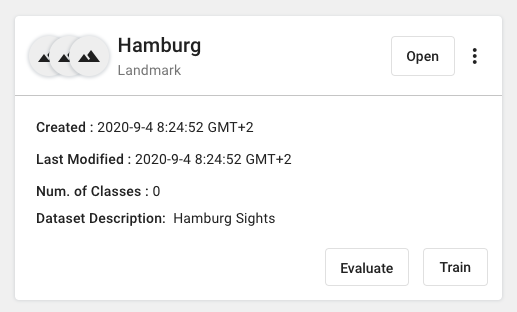
Open that dataset to add classes and images.
To create a class, click on “Add a New Class”. Enter a class name and submit.
To add images to your class, open it and upload images to that class. It is recommended to have at least three images per class for adequate results in the analysis.
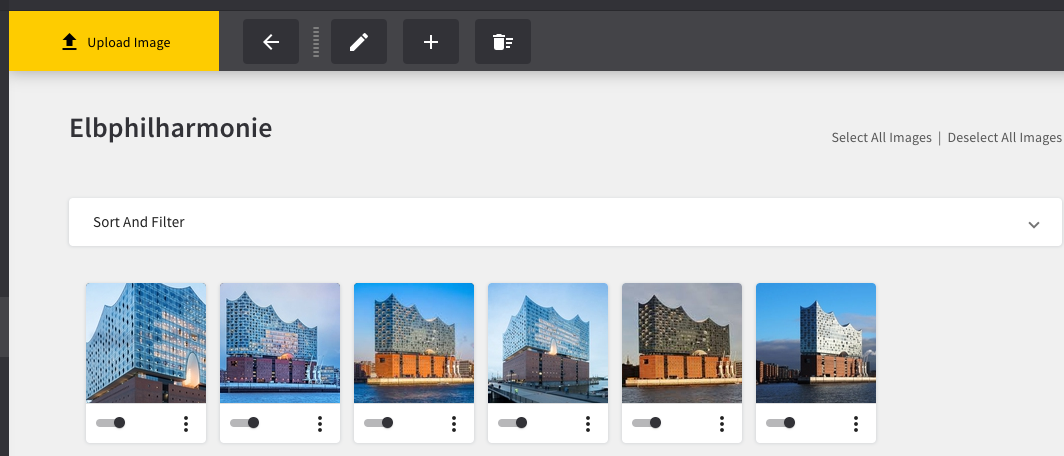
How to train an AI model
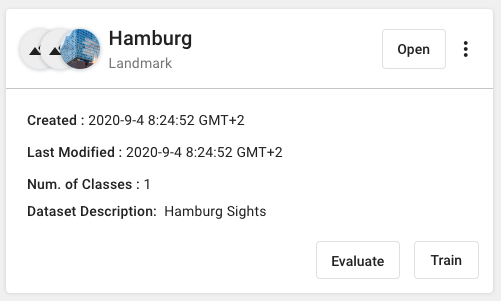
Once your images are uploaded, go back to “Datasets” in the menu on the left. Now it is time to train your own AI model. To do so, click on “Train”.
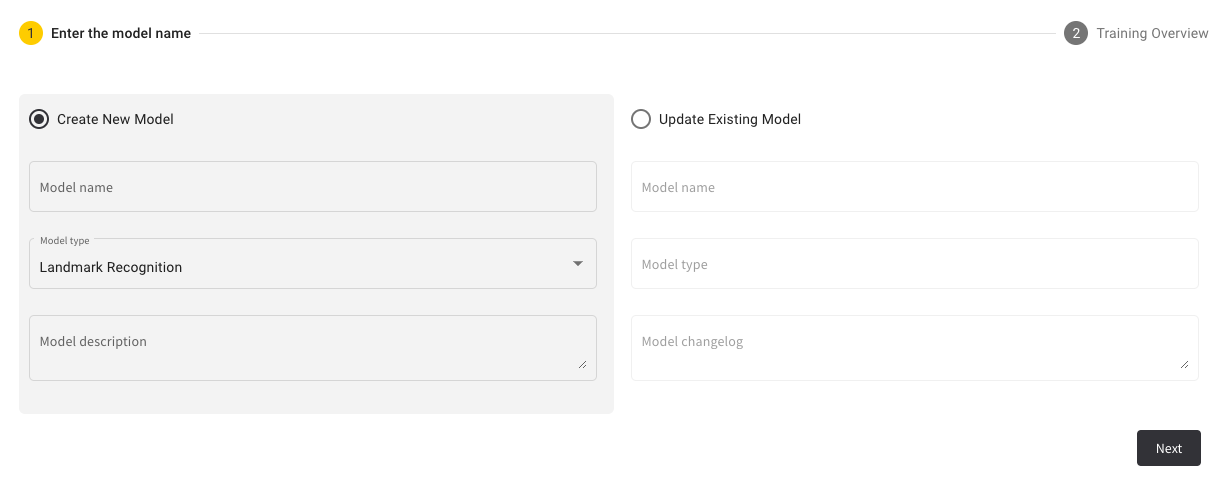
You are given two options now, in this case, you want to create a new AI model. You can enter the model name, the model type and a model description. Click on “Next” to continue.
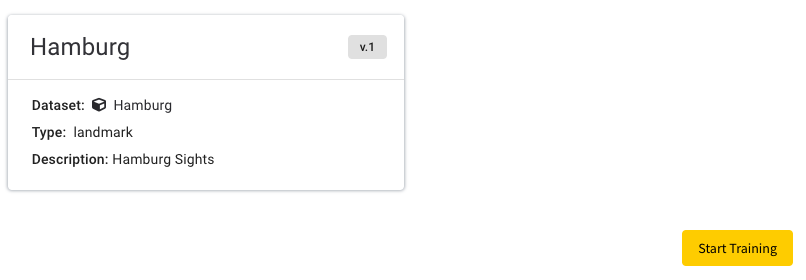
Check your AI model on the next page and click on “Start Training” to create it.
After that, your own AI model will appear in the “AI Models” section in the menu on the left.

From now on, you can use your own AI model to analyze images and videos. When you choose a visual mining module for your job, simply choose your own model.
Remember that you always have to train an AI model based on an already created dataset in order to integrate classes and images in your analysis.
How to generate training data automatically
If you have created a dataset for Face Recognition, DeepVA offers the possibility to add classes to that dataset automatically. If your images or videos show on-screen text inserts (“lower thirds”), the corresponding names and faces will be automatically added to your own dataset. To initiate that process, you have to start a job. Choose “Face Dataset Creation” as your mining module and type in the dataset ID of the dataset you want to add classes to.

You find the dataset ID under “Datasets” in the menu on the left if you click on the dataset you want to know the ID of.
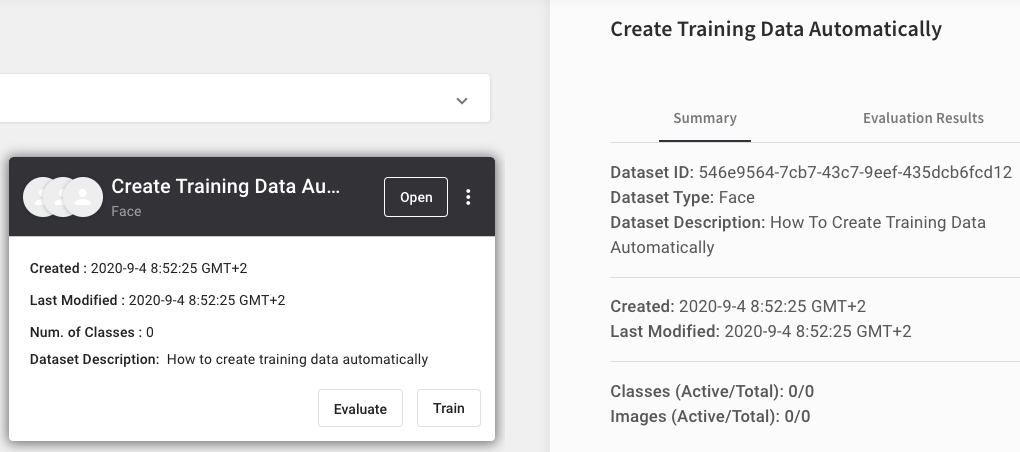
Fill in the ID under “Dataset ID” and start your job.
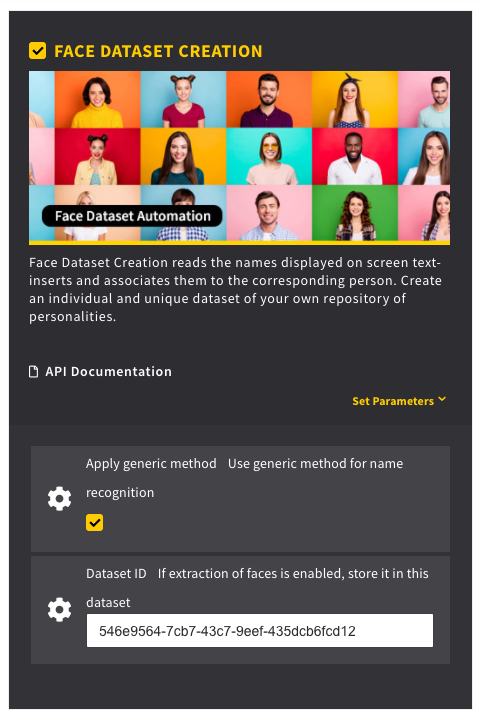
Once the job is finished, every person that is shown via lower third on-screen text inserts is added to your dataset. To use that dataset in your analysis you have to train an AI model based on the dataset. To do so, follow these steps. You can also train AI models by navigating to “AI Models” in the menu on the left and click on “Start Training”.